In LaTeX gibt es mehrere Möglichkeiten „in die nächste Zeile zu springen“.
Zum einen kann ein Text in inhaltliche Einheiten („Absätze“) eingeteilt werden. Absätze zeichnen sich in der Regel dadurch aus, dass die erste Zeile eingerückt ist, und ein einen Abstand zwischen zwei Absätzen gibt. Absätze können entweder durch eine einfache Leerzeile oder durch den Befehl \par erzeugt werden:
1
2
3
4
Text des ersten Absatzes. Die erste Zeile des ersten Absatzes eines Kapitels/Section,... ist in der Regel nicht eingerückt.
Text des zweiten Absatzes. Dieser wird durch eine leere Zeile nach dem ersten Absatz erzeugt.\par
Text des dritten Absatzes. Dieser wird durch den Befehl \\par erzeugt.
Text des ersten Absatzes. Die erste Zeile des ersten Absatzes eines Kapitels/Section,... ist in der Regel nicht eingerückt.
Text des zweiten Absatzes. Dieser wird durch eine leere Zeile nach dem ersten Absatz erzeugt.\par
Text des dritten Absatzes. Dieser wird durch den Befehl \\par erzeugt.
Eine weitere Möglichkeit, die man allerdings nur in Ausnahmefällen verwenden sollte, sind Zeilenumbrüche. Diese teilen den Text nicht in logische Abschnitte ein, sondern veranlassen LaTeX nur in die nächste Zeile zu springen. Eine Einrückung der ertsen Zeile oder ein Abstand zum vorhergehenden Text erfolgt nicht. Mir fällt auch kein Beispiel ein, in dem ein Zeilenumbruch innerhalb eines laufenden Textes sinnvoll verwendet werden kann. Man kann einen Zeilenumbruch durch die Befehle \\ und \newline erzeugen.
Manchmal möchte man Einträge für Kapitel im Inhaltsverzeichnis finden, allerdings ohne Nummerierung. Haufig findet man dies für Anhänge, Danksagungen, etc., da diese nicht zum eigentlichen Inhalt der Arbeit gehören.
In der Regel teilt man dazu die Arbeit in verschiedene Bereiche ein (siehe auch WikiBooks):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
\begin{document}\frontmatter% Römische Seitenzahlen, Chapter ohne Nummerierung% Titelseite, Summaries, Inhaltsverzeichnis,...\mainmatter% Nummerierte Chapter, Arabische Seitenzahlen% Einleitung, Methoden, Ergebnisse, Diskussion, (Referenzen),...\appendix% Chapter beginnen mit einem Buchstaben% Anhänge, (Glossar, Index),...\backmatter% Chapter ohne Nummerierung% Danksagung, ERklärung, Lebenslauf,...\end{document}
Wer diese Einteilung nicht nutzen möchte, kann auch manuell Einträge zum Inhaltsverzeichnis („table of contents“, TOC) hinzufügen. Dazu erstellt man mit Hilfe des * einen Eintrag, der nicht zum Inhaltsverzeichnis hinzugefügt wird. Im Anschluss fügt man den Eintrag manuell hinzu
In LaTeX kann man das aktuelle Datum in einen Text einfügen. In der Präambel findet man z.B. häufig die Angabe:
\date{\today}
\date{\today}
Dieser Befehl fügt in den Titel des Dokumentes das aktuelle Datum ein, z.B. October 2, 2013.
Manchmal möchte man allerdings nur die aktuelle Jahreszahl, den Monat oder den Tag in das Dokument einfügen. Diese Zahlen sind in den TeX-Primitiven \year, \month, \day gespeichert und können mit Hilfe von \the oder \number in das Dokument eingefügt werden.
\documentclass[a4paper]{article}\usepackage[english,ngerman]{babel}\begin{document}%% Die Ausgabe von \today ist abhängig von der Sprache:
Deutsche Ausgabe: \today\selectlanguage{english}\\
Englische Ausgabe: \today\\%% Einzelne Werte einfügen
Aktueller Tag: \the\day\\
Aktueller Monat: \the\month\\
Aktuelles Jahr: \the\year\end{document}
\documentclass[a4paper]{article}
\usepackage[english,ngerman]{babel}
\begin{document}
%
% Die Ausgabe von \today ist abhängig von der Sprache:
Deutsche Ausgabe: \today
\selectlanguage{english}\\
Englische Ausgabe: \today \\
%
% Einzelne Werte einfügen
Aktueller Tag: \the\day\\
Aktueller Monat: \the\month\\
Aktuelles Jahr: \the\year
\end{document}
Weitere Beispiele und Details finden sich auf WikiBooks.org.
Seit ich mit LaTeX begonnen habe, habe ich viele Pakete kennengelernt und eigene Befehle entwickelt. Alle haben irgendwo einen Platz in der Präambel gefunden. Problematisch wird es, wenn ich mit alten LaTex-Dokumenten arbeite, in denen ich bestimmte Befehle noch nicht verwendet habe. Oder wenn ich die Präambel eines Dokumentes kopiere, in dem unnötige Pakete eingebunden werden. Oftmals vergesse ich auch altenative Parameter, die man für ein Paket verwenden kann.
Da das alles sehr lästig ist, beginne ich jetzt diese Liste mit Befehlen aus meinen Präambeln. Dabei stelle ich kurz vor, warum ich ein Paket verwende und welche Prameter man verwenden kann.
12pt – Angabe der Schriftgröße in Punkten (Standard: 10pt)
titlepage – Nach dem Dokumententitel eine neue Seite beginnen (Standard bei book und report; bei article ist der Standard notitlepage)
twocolumn – Teile die Seiten in zwei Spalten auf (Standard: onecolumn)
openright, openany – Sollen Kapitel immer auf der rechten Seite begonnen werden?
1
\pagestyle{headings}
\pagestyle{headings}
In LaTeX gibt es drei verschiedene Seitenlayouts:
plain – Setze die Seitenzahl zentriert unten auf die Seite.
headings – Zeige Seitenzahl und Kapitelnamen in der Kopfzeile jeder Seite an.
empty – Zeige weder Seitenzahlen, noch Kapitelnamen an.
Sprache und Zeichensatz
1
\usepackage[english]{babel}
\usepackage[english]{babel}
Verschiedene Sprachen haben auch verschiedene Trennungsregeln. Unter anderem werden diese in Paket babel definiert.
english – englische Trennungsregeln verwenden
ngerman – deutsche Trennungsregeln verwenden (neue Rechtschreibung)
german – deutsche Trennungsregeln verwenden (alte Rechtschreibung)
ngerman,english – deutsche und englische Trennungsregeln laden (z.B. bei mehrsprachigen Dokumenten). Im Dokument die aktiven Trennungsregeln umschalten mit:
\selectlanguage{ngerman}
\selectlanguage{ngerman}
1
2
3
\usepackage{ucs}% Unicode (u.A. UTF-8) hinzuladen!\usepackage[utf8x]{inputenc}% Verwende UTF-8 als Zeichensatz.\usepackage[T1]{fontenc}% Trennung von Umlauten ermöglichen(?)
\usepackage{ucs} % Unicode (u.A. UTF-8) hinzuladen!
\usepackage[utf8x]{inputenc} % Verwende UTF-8 als Zeichensatz.
\usepackage[T1]{fontenc} % Trennung von Umlauten ermöglichen(?)
Sofern man Sonderzeichen aus mehreren Sprachen in einem Dokument verwendet (z.B. Sonderzeichen in den Autorennamen der Literaturliste), sollte man den Unicode-Zeichensatz UTF-8 als Zeichensatz seines Dokumentes verwenden. Das Dokument selbst sollte dann auch in diesem Zeichensatz gespeichert werden. Man sollte auch beachten, dass zusätzliche Dokumente wie .bib-Dateien auch im UTF-8 Zeichensatz gespeichert werden müssen. Im Referenzmanager JabRef kann man unter file / database properties / encoding UTF-8 einstellen!
Beispiel
Ein Dokument mit den oben beschriebenen Werten für die Präambel könnte folgendermaßen aussehen:
1
2
3
4
5
6
7
8
9
10
11
12
% Dokumententyp\documentclass[a4paper,twoside,12pt]{scrartcl}\pagestyle{headings}% Sprache und Zeichensatz\usepackage[english]{babel}\usepackage{ucs}% Unicode (u.A. UTF-8) hinzuladen!\usepackage[utf8x]{inputenc}% Verwende UTF-8 als Zeichensatz.\usepackage[T1]{fontenc}% Trennung von Umlauten ermöglichen(?)\begin{document}
Text
\end{document}
% Dokumententyp
\documentclass[a4paper,twoside,12pt]{scrartcl}
\pagestyle{headings}
% Sprache und Zeichensatz
\usepackage[english]{babel}
\usepackage{ucs} % Unicode (u.A. UTF-8) hinzuladen!
\usepackage[utf8x]{inputenc} % Verwende UTF-8 als Zeichensatz.
\usepackage[T1]{fontenc} % Trennung von Umlauten ermöglichen(?)
\begin{document}
Text
\end{document}
Abschlussarbeiten oder Publikationen können oft viel Text enthalten. Große LaTeX-Dateien werden allerdings sehr schnell unübersichtlich. Daher kann man z.B. Kapitel, Deckblätter, Glossare,… in eigene Dateien auslagern. Diese Dateien werden dann in einer Haupt-Datei wieder zusammengeführt, indem man sie mit dem Befehl \input() einbindet. Im Vergleich zu include() kann input():
innerhalb der Präambel verwendet werden (z.B. für ein Glossar)
innerhalb einer mit input() eingefügten Datei verwendet werden (Verschachtelung)
verwendet werden, ohne das zwingend ein Zeilenumbruch erfolgt
Angenommen die Abschlussarbeit befindet sich in der Datei arbeit.tex. Diese könnte z.B. folgenden Inhalt haben:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
\documentclass[12pt,twoside]{article}\title{Meine Abschlussarbeit}\author{Max Mustermann}\date{\today}\begin{document}\maketitle\tableofcontents{}\input{einleitung}% binde die Datei einleitung.tex ein\input{methoden}% binde die Datei methoden.tex ein% ... (weitere Dateien Einbinden)\end{document}
\documentclass[12pt,twoside]{article}
\title{Meine Abschlussarbeit}
\author{Max Mustermann}
\date{\today}
\begin{document}
\maketitle
\tableofcontents{}
\input{einleitung} % binde die Datei einleitung.tex ein
\input{methoden} % binde die Datei methoden.tex ein
% ... (weitere Dateien Einbinden)
\end{document}
In diesem Falle muss es zwei weitere Dateien geben: einleitung.tex und methoden.tex.
Diese beiden Dateien entahlten die Inhalte, die mit Hilfe der Datei arbeit.tex zusammengefügt werden.
In der Datei einleitung.tex könnte Folgendes stehen:
1
2
3
% !TEX root = arbeit.tex\section{Einleitung}
Einführung in die Thematik dieser Arbeit.
% !TEX root = arbeit.tex
\section{Einleitung}
Einführung in die Thematik dieser Arbeit.
In der Datei methoden.tex könnte z.B. folgender Inhalt stehen:
Die einzelnen Dateien für die Sections haben dabei keine eigene Präambel und kein eigenes \begin{document}. Arbeitet man also an einer dieser Dateien und startet aus seinem Editor heraus latex/pdflatex für diese Datei, bekommt man in der Regel eine Fehlermeldung:
! LaTeX Error: Missing \begin{document}.
Daher sollte man zu Beginn jeder Datei die Zeile % !TEX root = arbeit.tex hinzufügen. Diese Zeile teilt LaTeX mit, welches die Haupt-Datei (root = Wurzel) der Arbeit ist. Im Anschluss verwendet LaTeX anstatt der aktuellen Datei immer die Haupt-Datei (hier: arbeit.tex) zum setzen und nicht die aktuell bearbeitete Datei.
Siehe dazu auch codepills.
Ich habe gerade eben folgende Fehlermeldung nach dem Start von Ubuntu bekommen:
Auf dem Datenträger „Wurzelordner des Dateisystems“ ist nur noch XXX kB Speicherplatz verfügbar.
In meinem Falle war XXX gleich 0. Es war also höchste Zeit, dass ich mal wieder unnötige Dateien von meiner System-Partition lösche. Ich hatte allerdings längst wieder vergessen, was man alles machen kann. Daher habe ich nun eine kleine Liste zusammengestellt:
Zunächst habe ich den Inhalt des temporären Verzeichnisses gelöscht.
1
2
# Temporäreres Verzeichnis leerenrm-r/tmp/*
# Temporäreres Verzeichnis leeren
rm -r /tmp/*
Darin hatten sich Fehlermeldungen von apport angesammelt, die bei Programmabstürzen erstellt worden waren. Teilweise konnten diese aber nicht abgesendet werden, weil keine Internetverbindung bestand. In meinem Falle hatten sich über die Jahre mehr als 1.5 GB angesammelt.
Im Anschluss habe ich heruntergeladene Paket-Dateien, sowie nicht mehr benötigte Pakete gelöscht:
1
2
3
4
# Paketdateien löschensudoapt-get clean# Nicht mehr benötigte Pakete löschensudoapt-get--purge autoremove
# Paketdateien löschen
sudo apt-get clean
# Nicht mehr benötigte Pakete löschen
sudo apt-get --purge autoremove
Letzterer Befehl hat früher scheinbar auch nicht mehr benötigte Kernel-Versionen gelöscht (UbuntuUsers Forum). Das ist jetzt allerdings nicht mehr der Fall.
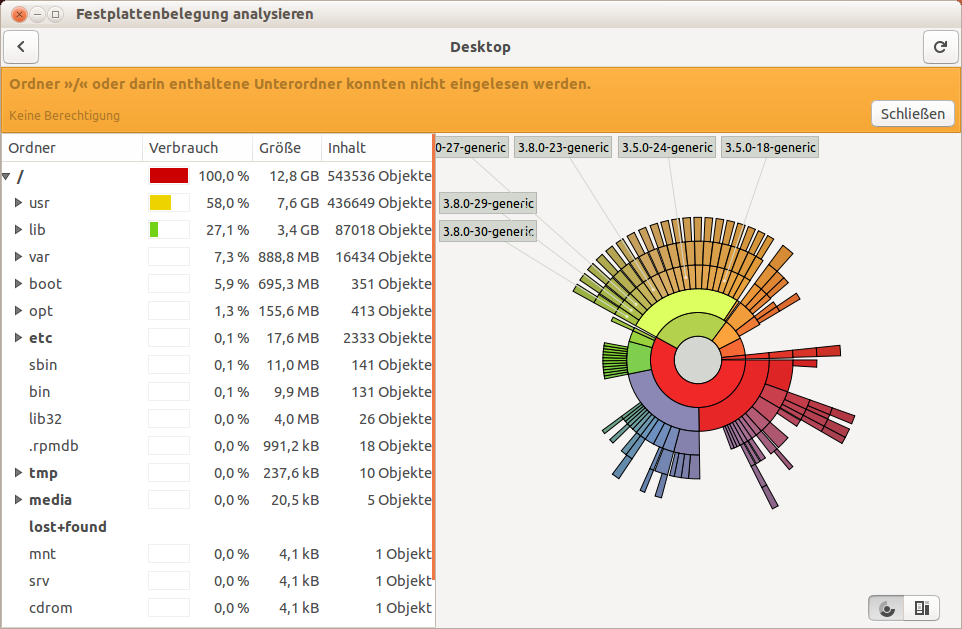
In regelmäßigen Abständen sollte man auch das Programm baobab („Festplattenbelegung analysieren“) aufrufen. Damit kann man herausfinden, welche Verzeichnisse besonders viele Daten enthalten. In meinem Falle habe ich gesehen, dass sich viele Kernel-Versionen angesammelt hatten (Ordner: /usr/src und /lib/modules):
Das Programm „baobab“ stellt die Größe von Ordnern grafisch dar. In diesem Fall kann man erkennen, dass ein großer Teil der Partition mit alten Kernel-Versionen belegt ist.
Wie im UbuntuUsers-Forum beschrieben, kann man im Terminal ähnlich vorgehen:
1
2
# Platzbedarf der Ordner im Wurzelverzeichnis anzeigensudodu-h/--max-depth=1
# Platzbedarf der Ordner im Wurzelverzeichnis anzeigen
sudo du -h / --max-depth=1
Im Anschluss kann man sich weiter auf die Suche machen und z.B. eine Liste der installierten Kernel-Versionen ausgeben lassen:
Gewünscht=Unbekannt/Installieren/R=Entfernen/P=Vollständig Löschen/Halten
| Status=Nicht/Installiert/Config/U=Entpackt/halb konFiguriert/
Halb installiert/Trigger erWartet/Trigger anhängig
|/ Fehler?=(kein)/R=Neuinstallation notwendig (Status, Fehler: GROSS=schlecht)
||/ Name Version Architektur Beschreibung
+++-============================================-===========================-===========================-==============================================================================================
un linux-image-2.6 <keine> (keine Beschreibung vorhanden)
rc linux-image-2.6.35-22-generic 2.6.35-22.35 amd64 Linux kernel image for version 2.6.35 on x86/x86_64
rc linux-image-2.6.35-23-generic 2.6.35-23.41 amd64 Linux kernel image for version 2.6.35 on x86/x86_64
rc linux-image-2.6.35-24-generic 2.6.35-24.42 amd64 Linux kernel image for version 2.6.35 on x86/x86_64
rc linux-image-2.6.35-25-generic 2.6.35-25.44 amd64 Linux kernel image for version 2.6.35 on x86/x86_64
rc linux-image-2.6.35-27-generic 2.6.35-27.48 amd64 Linux kernel image for version 2.6.35 on x86/x86_64
rc linux-image-2.6.35-28-generic 2.6.35-28.50 amd64 Linux kernel image for version 2.6.35 on x86/x86_64
rc linux-image-2.6.38-10-generic 2.6.38-10.46 amd64 Linux kernel image for version 2.6.38 on x86/x86_64
ii linux-image-2.6.38-11-generic 2.6.38-11.50 amd64 Linux kernel image for version 2.6.38 on x86/x86_64
rc linux-image-2.6.38-8-generic 2.6.38-8.42 amd64 Linux kernel image for version 2.6.38 on x86/x86_64
un linux-image-3.0 <keine> (keine Beschreibung vorhanden)
rc linux-image-3.0.0-12-generic 3.0.0-12.20 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
rc linux-image-3.0.0-13-generic 3.0.0-13.22 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
rc linux-image-3.0.0-14-generic 3.0.0-14.23 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
rc linux-image-3.0.0-15-generic 3.0.0-15.26 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
rc linux-image-3.0.0-16-generic 3.0.0-16.29 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
rc linux-image-3.0.0-17-generic 3.0.0-17.30 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
ii linux-image-3.0.0-19-generic 3.0.0-19.33 amd64 Linux kernel image for version 3.0.0 on x86/x86_64
rc linux-image-3.2.0-24-generic 3.2.0-24.39 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
rc linux-image-3.2.0-25-generic 3.2.0-25.40 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
rc linux-image-3.2.0-26-generic 3.2.0-26.41 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
rc linux-image-3.2.0-27-generic 3.2.0-27.43 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
rc linux-image-3.2.0-29-generic 3.2.0-29.46 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
rc linux-image-3.2.0-30-generic 3.2.0-30.48 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
rc linux-image-3.2.0-31-generic 3.2.0-31.50 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
ii linux-image-3.2.0-32-generic 3.2.0-32.51 amd64 Linux kernel image for version 3.2.0 on 64 bit x86 SMP
ii linux-image-3.5.0-17-generic 3.5.0-17.28 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-18-generic 3.5.0-18.29 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-19-generic 3.5.0-19.30 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-21-generic 3.5.0-21.32 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-22-generic 3.5.0-22.34 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-23-generic 3.5.0-23.35 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-24-generic 3.5.0-24.37 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-25-generic 3.5.0-25.39 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-26-generic 3.5.0-26.42 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-3.5.0-27-generic 3.5.0-27.46 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
rc linux-image-3.8.0-19-generic 3.8.0-19.30 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-21-generic 3.8.0-21.32 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-23-generic 3.8.0-23.34 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-25-generic 3.8.0-25.37 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-26-generic 3.8.0-26.38 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-27-generic 3.8.0-27.40 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-29-generic 3.8.0-29.42 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-3.8.0-30-generic 3.8.0-30.44 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-17-generic 3.5.0-17.28 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-18-generic 3.5.0-18.29 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-19-generic 3.5.0-19.30 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-21-generic 3.5.0-21.32 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-22-generic 3.5.0-22.34 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-23-generic 3.5.0-23.35 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-24-generic 3.5.0-24.37 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-25-generic 3.5.0-25.39 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-26-generic 3.5.0-26.42 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
ii linux-image-extra-3.5.0-27-generic 3.5.0-27.46 amd64 Linux kernel image for version 3.5.0 on 64 bit x86 SMP
rc linux-image-extra-3.8.0-19-generic 3.8.0-19.30 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-21-generic 3.8.0-21.32 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-23-generic 3.8.0-23.34 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-25-generic 3.8.0-25.37 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-26-generic 3.8.0-26.38 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-27-generic 3.8.0-27.40 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-29-generic 3.8.0-29.42 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-extra-3.8.0-30-generic 3.8.0-30.44 amd64 Linux kernel image for version 3.8.0 on 64 bit x86 SMP
ii linux-image-generic 3.8.0.30.48 amd64 Generic Linux kernel image
Da bei mir vor allem die Zahl der alten Linux-Kernel ein Problem war, habe ich einige davon gelöscht. Wie im Wiki von UbuntuUsers beschrieben, habe ich dazu in der Paketverwaltung Synaptic nach
linux-image-
linux-headers-
gesucht und entsprechende Pakete vollständig entfernt. Mindestens eine ältere Version sollte man allerdings behalten. Dadurch habe ich 3.5GB frei machen können.
Große Dateien können sich auch im Verzeichnis /var/log ansammeln. Das war bei mir allerdings nicht der Fall, was ich folgenden Befehlen überprüft habe:
# Dateien sortiert nach Nutzungsdatum auflistenls-aluh/var/log
# Größe des gesamten Ordners ausgeben lassensudodu-sh/var/log
# Dateien sortiert nach Nutzungsdatum auflisten
ls -aluh /var/log
# Größe des gesamten Ordners ausgeben lassen
sudo du -sh /var/log
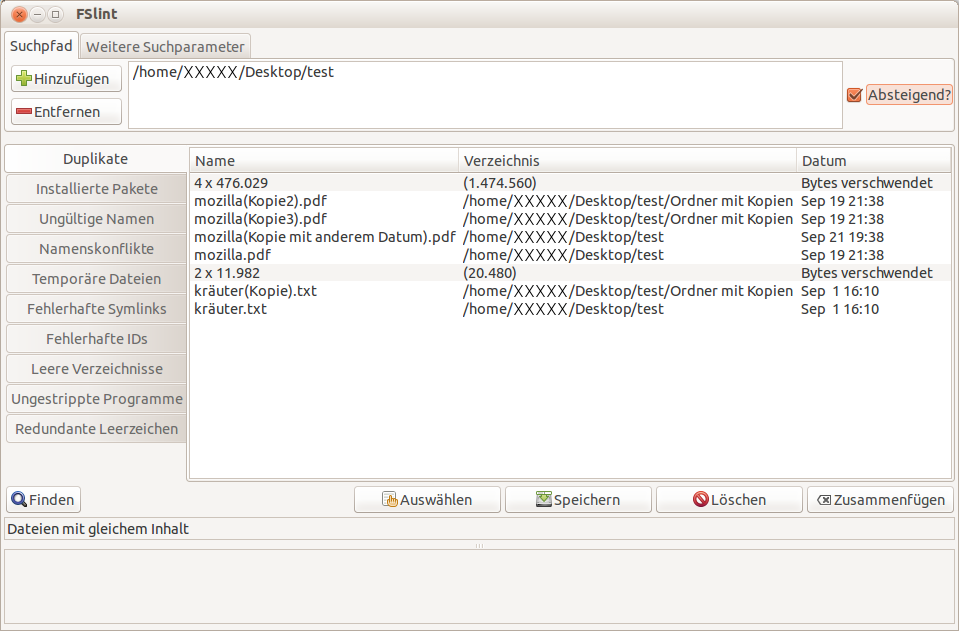
Wenn man im eigenen Home-Verzeichnis Ordnung schaffen möchte, bietet sich das Programm FSlint an. Nach der Installation des Programmpaketes fslint, lässt sich das Programm über den Befehl fslint-gui starten. Im Anschluss kann man viele ungenutzte Dateien und Ordner suchen und ggf. direkt löschen:
Duplikate
Temporäre Dateien (außerhalb des Verzeichnisses /tmp)
Leere Verzeichnisse
Fehlerhafte Symlinks
…
Das Programm FSlint kann unter anderem Dateien mit identischem Inhalt finden. Dabei spielt es keine Rolle, ob die Dateien unterschiedliche Namen oder Erstellungsdaten haben.
Der ein oder andere kennt das Problem: der Rechner funktioniert nicht, und man muss ins Wiederherstellungs-Terminal. Zu dem Zeitpunkt ist allerdings die korrekte Tastaturbelegung noch nicht geladen. Man hat zwar eine deutsche Tastatur angeschlossen, aber die gedrückten Tasten (deren Signale) werden so interpretiert, als handele es sich um eine englische Tastatur. Dann geht das suchen los, denn Passwörter und Terminal-Befehle wollen richtig eingegeben werden.
Die folgende kleine Liste enthält häufig benötigte Zeichen, sowie die Taste oder Tastenkombination, die dazu auf einer deutschen Tastatur gedrückt werden muss.
Manchmal liegen in R Daten in Form einer Liste vor (z.B. die Ausgabe der Funktion hist()). In einer Liste können Daten enthalten sein, die eine unterschiedliche Länge haben. Im Falle von hist() sind z.B. Arrays unterschiedlicher Länge gemeinsam mit einfachen Variablen in einer Liste kombiniert.
Für weitere Analysen kann es jedeoch hilfreich sein, die gleich langen Teile in einen separaten data.frame auszulagern. Dann kann z.B. mit Hilfe der Funktion subset() relativ einfach Bereiche aus den Daten herausfiltern.
In R gibt es keine vorgefertigte Funktion, die direkt Daten vom Typ list in Daten vom Typ data.frame konvertieren kann. Das liegt daran, dass in einem data.frame alle enthaltenen Variablen (in der Regel Arrays) die gleiche Länge haben müssen. Unsere Entscheidung, welche Variablen aus der Liste in den data.frame übernommen werden sollen, müssen wir R mitteilen.
Das folgende Beispiel zeigt, wie man das sehr einfach bewerkstelligen kann:
1
2
3
4
5
6
7
8
# Liste mit Arrays ("x", "y", "sd") und einer Variablen ("name")
liste =list(x=c(1:5), y=c(11:15), sd=c(0,1,2,0,0), name="Meine Liste")# data.frame ("df") erzeugen mit den Variablen "x", "y" und "sd"df=with(data=liste, expr=data.frame(x, y))# Struktur des data.frames ausgebenstr(df)
# Liste mit Arrays ("x", "y", "sd") und einer Variablen ("name")
liste = list(x=c(1:5), y=c(11:15), sd=c(0,1,2,0,0), name="Meine Liste")
# data.frame ("df") erzeugen mit den Variablen "x", "y" und "sd"
df = with(data=liste, expr=data.frame(x, y))
# Struktur des data.frames ausgeben
str(df)
'data.frame': 5 obs. of 3 variables:
$ x : int 1 2 3 4 5
$ y : int 11 12 13 14 15
$ sd: num 0 1 2 0 0
Im Anschluss kann man sehr einfach nur bestimmte Teile des data.frame ausgeben lassen.
Das kann man z.B. direkt über den Index (df[zeile, spalte]) oder über die Funktion subset() machen.
1
2
3
4
5
6
7
8
9
# Nur das zweite und vierte Element (Zeile) anzeigendf[c(2,4),]# Nur die Elemente (Zeilen) anzeigen, bei denen x>2 istdf[(df$x>2),]# Nur die Elemente (Zeilen) der Variablen (Spalten) x und y ausgeben,# bei denen sd<1 und x>2 istsubset(df, subset=(x>2& sd<1), select=c(x,y))
# Nur das zweite und vierte Element (Zeile) anzeigen
df[c(2,4),]
# Nur die Elemente (Zeilen) anzeigen, bei denen x>2 ist
df[(df$x>2),]
# Nur die Elemente (Zeilen) der Variablen (Spalten) x und y ausgeben,
# bei denen sd<1 und x>2 ist
subset(df, subset=(x>2 & sd<1), select=c(x,y))
Stell Dir vor, Du hast die Länge von 1000 Fischen gemessen. Im Anschluss möchtest Du die eine Häufigkeitsverteilung (Histogramm) der Größen erstellen. Je nachdem wie genau du gemessen hast, wirst du keine zwei Fische mit der gleichen Länge finden. Daher bist Du gut beraten, die Daten zunächst in bestimmte Längenklassen einzuteilen (z.B. „Anzahl von Fischen zwischen 23cm und 24cm“). Für diese Klassifizierung (binning) steht Dir in R die Funktion hist() zur Verfügung.
Nehmen wir mal an, die Längen der Fische folgen einer Normalverteilung. Im Durschnitt haben die Fische eine Länge von 25cm (± 5cm)
1
2
3
# Ziehe Eintausend Zufallszahlen aus einer Normalverteilung# (Mittelwert: 25; Standardabweichung: 5)
laengen =rnorm(n=1e3, mean=25, sd=5)
# Ziehe Eintausend Zufallszahlen aus einer Normalverteilung
# (Mittelwert: 25; Standardabweichung: 5)
laengen = rnorm(n=1e3, mean=25, sd=5)
Mit der Funktion hist() kannst Du die Daten nun in Klassen einteilen und plotten lassen.
1
2
3
# Klassifiziere die Daten# (=Erstelle eine Histogramm und stelle es dar)
gebinnt =hist(laengen, plot=TRUE)
# Klassifiziere die Daten
# (=Erstelle eine Histogramm und stelle es dar)
gebinnt = hist(laengen, plot=TRUE)
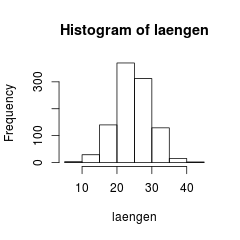
Automatisch erstelltes Histogramm der Beispieldaten. Die Klassengrenzen wurden von R bestimmt.
hist() erstellt nun eine list, in der die Klassengrenzen (breaks), die Häufigkeiten (counts), Dichten (densitiy) und Klassenmitten (mids), sowie der Name der ursprünglichen Variable (xname) und die Information, ob die Klassen alle gleich groß sind (equidist), gespeichert werden:
Du hast natürlich auch die Möglichkeit, selbst Klassengrenzen (breaks) anzugeben. Die Klassen müssen auch nicht alle gleich Groß sein. Bei einigen Daten können z.B. logarithmische Bin-Größen sinnvoll sein.
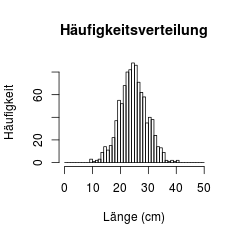
Histogramm mit selbst gewählten Klassengrenzen (hier: Klassenbreite=1cm)
Hierbei muss man allerdings darauf achten, dass keiner der Werte ausgeschlossen wurde, weil er ausserhalb der gewählten Klassen lag bzw. auf die untere (oder obere) Klassengrenze gefallen ist.
Fehler in hist.default(laengen, plot = T, breaks = c(15:50), xlab = "Länge (cm)", :
einige 'x' nicht gezählt: evtl. überdecken die 'breaks' nicht den gesamten Bereich von 'x'
Daher sollte man immer prüfen, ob die Summe der Werte in den Klassen auch tatsächlich der Stichprobengröße entspricht.
# Sind alle Messwerte der Stichpobe im Histogramm berücksichtigt?sum(gebinnt$counts)
# Sind alle Messwerte der Stichpobe im Histogramm berücksichtigt?
sum(gebinnt$counts)
Eventuell muss man dann weitere Klasse hinzunehmen, bzw. die untere (oder obere) Klassengrenze zu einer Klasse hinzu zählen (Option include.lowest=T).
Alternativen
Alternativ zur Funktion hist() könnte man ein Histogramm auch durch die Anwendung der Funktion table() auf gerundete Daten (round()) erstellen: table(round(daten)).
Die Funktion table() ist dazu gedacht die „Anzahl gleicher Werte zu ermitteln“. Das entspricht aber nicht ganz dem Gedanken der Klassifizierung.
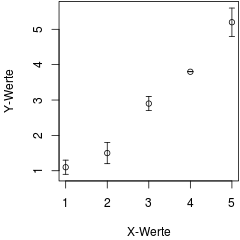
In wissenschaftlichen Publikationen werden häufig Messwerte in Grafiken dargestellt. Messungen sind allerdings immer fehlerbehaftet. Daher sollte man dem Leser mitteilen, wie verlässlich die gemessenen Werte sind. In der deskriptiven Statistik gibt es dafür diverse Kennzahlen, wie z.B. die Standardabweichung oder den Standardfehler. Diese werden oft als Fehlerbalken in die Grafiken eingefügt.
Grafisch dargestellte Messwerte mit Fehlerbalken.
In R gibt es leider keine Standardmethode, die diese Aufgabe übernimmt. Zunächst hatte ich nach Anleitungen im Internet eigene Funktionen für diese Aufgabe erstellt.
Eine Lösung fand ich bei Stackoverflow. Allerdings wurden hier die horizontalen Linien bei einer logarithmischen X-Achse nicht korrekt angezeigt (links und rechts waren die Linien unterschiedlich lang).
Die Lösung von MonkeysUncle war in der Hinsicht besser. Allerdings wurde keine horizontale Linie angezeigt, wenn der Fehler 0 war. Zudem wurde gar kein Fehlerbalken angezeigt, wenn die untere Grenze des Fehlers (bei logarithmischer Y-Achse) im negativen Bereich lag.
Schließlich habe ich die Funktion errbar() im Paket Hmisc gefunden (siehe auch StackOverflow). Hier werden:
Die horizontalen Linien auch bei logarithmischer X-Achse korrekt gezeichnet.
Bei logarithmischer Y-Achse und negativer unteren Fehlergrenze, wird zumindest die obere Fehlergrenze geplottet.
Eine horizontale Linie wird auch hinzugefügt, wenn der Fehler 0 ist.
Die Y-Ranges werden automatisch gewählt, wenn die Fehlerbalken ausserhalb der Grafik liegen würden.
Das folgende Beispiel zeigt, wie man Datenpunkte mit ihren Fehlerbalken in eine Grafik einträgt.
# Datenpunkte (x, y) mit einer Standardabweichung (sd)
daten =data.frame(
x =c(1:5)
, y =c(1.1, 1.5, 2.9, 3.8, 5.2)
, sd=c(0.2, 0.3, 0.2, 0.0, 0.4))# Paket "Hmisc" installieren und laden install.packages("Hmisc", dependencies=T)library("Hmisc")# Plot mit automatischer Wahl des Y rangeswith(data= daten
, expr = Hmisc::errbar(x, y, y+sd, y-sd, pch=1))# Datenpunkte mit Fehlerbalken zu einem# existierenden Koordinatensystem hinzufügen (add=T)plot(daten$x, daten$y, type="n", xlab="X-Werte", ylab="Y-Werte")with(data= daten
, expr = Hmisc::errbar(x, y, y+sd, y-sd, pch=2, add=T))
# Datenpunkte (x, y) mit einer Standardabweichung (sd)
daten = data.frame(
x = c(1:5)
, y = c(1.1, 1.5, 2.9, 3.8, 5.2)
, sd = c(0.2, 0.3, 0.2, 0.0, 0.4)
)
# Paket "Hmisc" installieren und laden
install.packages("Hmisc", dependencies=T)
library("Hmisc")
# Plot mit automatischer Wahl des Y ranges
with (
data = daten
, expr = Hmisc::errbar(x, y, y+sd, y-sd, pch=1)
)
# Datenpunkte mit Fehlerbalken zu einem
# existierenden Koordinatensystem hinzufügen (add=T)
plot(daten$x, daten$y, type="n", xlab="X-Werte", ylab="Y-Werte")
with (
data = daten
, expr = Hmisc::errbar(x, y, y+sd, y-sd, pch=2, add=T)
)
Die Funktion errbar() erweitert die Funktion plot(). Daher können die Grafikparameter von plot() und par() (hier z.B. pch) verwendet werden. Zusätzlich gibt es noch Parameter, mit denen sich z.B. die breite der horizontalen Begrenzung (cap) steuern lässt.