Im Gegensatz zu gnuplot, werden in R-Plots die logarithmische Achsen nicht sehr schön formatiert. Das Paket SFSmisc schafft hier Abhilfe. In diesem Artikel beschreibe ich Schritt für Schritt, wie man ansehnliche logarithmische Achsen für R-Plots erstellt.
- Als Beispiel sollen Daten geplottet werden, die in einem doppelt logarithmischen Plot eine Gerade ergeben:
x = 1:1000 y = x^-1.5
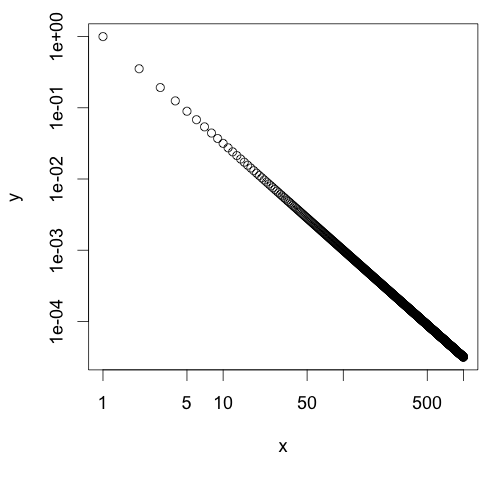
- Nun werden diese Daten mit dem Befehl plot() in einem Koordinatensystem mit logarithmischer X- und Y-Achse (
log="xy") dargestellt:plot(x, y, log="xy")
Dabei kann man erkennen, dass es keine kleinen Striche zur Unterteilung der Bereiche zwischen den einzelnen Größenordnungen gibt:
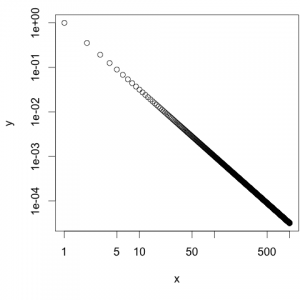
Plot mit logarithmischen Achsen. Standardmäßig werden keine Striche zwischen den Größenordnungen eingezeichnet. - Es ist aber durchaus üblich, den Bereich zwischen zwei Größenordnungen mit 8 kleinen Strichen zu unterteilen. Diese Striche zeigen an, an welchen Stellen 20%, 30%, 40%, 50%, 60%, 70%, 80% oder 90% der folgenden Größenordnung erreicht wurden. Um das in R zu bewerkstelligen, muss zunächst das Paket SFSmisc installiert werden (siehe dazu auch: Funktion aus einem bestimmten R-Paket laden):
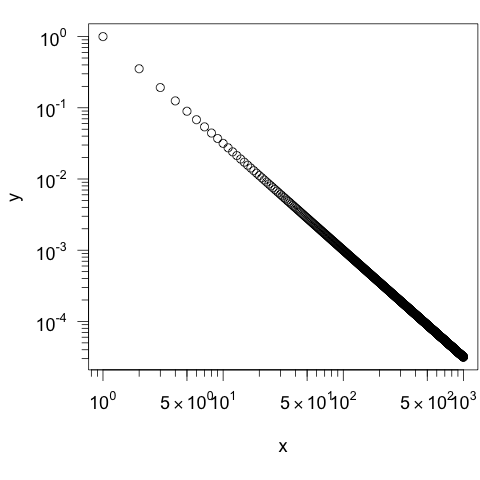
# Installation install.packages("sfsmisc", dependencies=T) # Paket laden library(package = "sfsmisc") - Im Anschluss plotten wir die Daten erneut, aber ohne dabei die Achsen zu beschriften (
xaxt="n", yaxt="n"). Die Beschriftung der Achsen wird im Anschluss mit Hilfe des Befehlseaxis()aus dem Paket SFSmisc hinzugefügt:plot(x, y, log="xy", xaxt="n", yaxt="n") sfsmisc::eaxis(side=1) # X-Achse sfsmisc::eaxis(side=2) # Y-Achse
Im neuen Plot sind nun auf jedenfall acht Striche zur Unterteilung einer Größenordnung zu sehen:
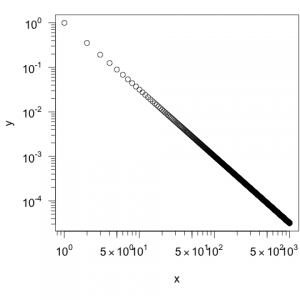
Erstellt man die Achsen eines Plots mit Hilfe des Befehls eaxis() aus dem Paket SFSmisc, so wird der Bereich zwischen zwei Größenordnungen in neun Teile unterteilt. Eventuell werden aber nicht nur die Zahlen für die Größenordnungen eingetragen, sondern auch für dazwischen liegende Werte (hier z.B. 5, 50 und 500). In diesem Beispiel wurde nicht explizit angegeben, welche Zahlen auf den Achsen zu sehen sein sollen. Daher sind nicht nur die Größenordnungen, sondern auch Werte dazwischen, als Zahlen eingetragen.
- Daher kann man nun noch explizit angeben, welche Zahlen sichtbar sein sollen (
at=)plot(x, y, log="xy", xaxt="n", yaxt="n") sfsmisc::eaxis(side=1, at=10^c(0:3)) sfsmisc::eaxis(side=2, at=10^c(-4,-2,0))
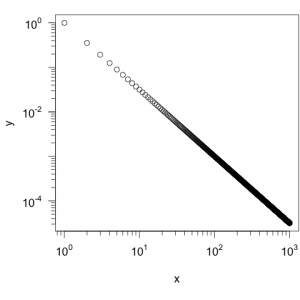
In diesem Plot wurden nur Zahlen für die Größenordnungen angegeben. Auf der X-Achse wurde jede, auf der Y-Achse nur jede zweite Größenordnung mit einer Zahl versehen.