Ich stelle viele meiner Daten in Plots mit zwei logarithmischen Achsen dar. Oftmals kommt es in solchen Plots auf die Steigung der Kurve an, also den Exponenten eines Power laws. In solchen Fällen zeichne ich, zusätzlich zu den Daten, eine oder mehrere Geraden mit einer Referenz-Steigung ein. Dadurch kann der Betrachter abschätzen, in welchen Bereichen die Daten eher zu der einen oder der anderen Steigung tendieren. Ich fand es allerdings immer sehr mühsam diese Steigungen einzuzeichnen. Grund: Ein Teil der Anfangs- oder Endkoordinaten musste im logarithmischen Raum berechnet werden. Daher habe ich mir eine Funktion geschrieben, die mir anhand einer Anfangs-Koordinate, der Steigung, sowie einem Teil der Endkoordinate, den fehlenden Wert berechnet und die Referenz-Gerade in den Plot einzeichnet.
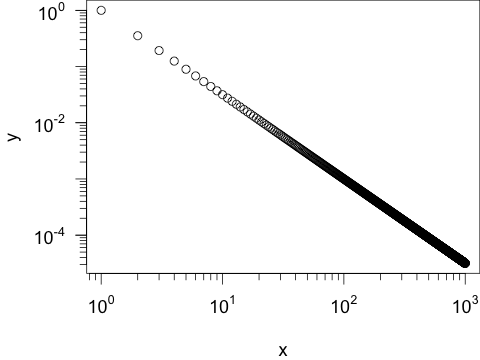
- Zunächst generiere ich Daten, die im doppelt-logarithmischen Plot eine Gerade ergeben:
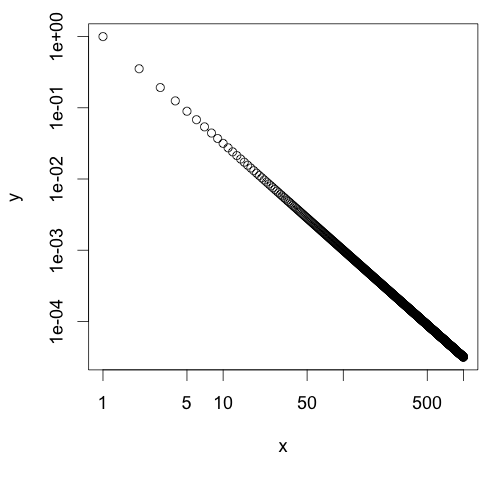
x = 1:1000 y = x^-1.5
- Diese werden dann mit schön formatierten Achsen geplottet, wie im Artikel „Logarithmische Achsen in R-Plots formatieren“ beschrieben.
library(package = "sfsmisc") #png("log-gerade.png", width=480, height=360) #par(cex =1.5, mar=c(4,4,0,0)+.01) plot(x, y, log="xy", xaxt="n", yaxt="n") sfsmisc::eaxis(side=1, at=10^c(0:3)) sfsmisc::eaxis(side=2, at=10^c(-4,-2,0)) #dev.off()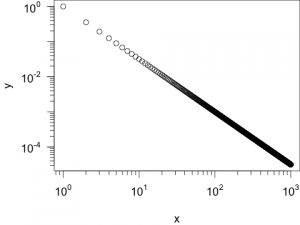
Darstellung einer Potenz-Funktion in einem Plot mit zwei logarithmischen Achsen. - Der Exponent der von mir verwendeten Potenzfunktion ist
-1.5. Daher ist auch die Steigung der Geradenm = -1.5. Nun möchte ich zusätzlich eine Gerade mit der Steigungm = -1in den Plot eintragen. Diese soll bei am Punkt (x1 = 101,y1 = 10-1) beginnen. Enden soll die Gerade beix2 = 2*102. Gesucht ist also die Y-Koordinate des Endpunktes (y2).Nun kann man:
- Alle vorhandenen x- und y-Werte logarithmieren (da beide Achsen logarithmisch sind).
- Diese Werte können in die Gleichung für die Berechnung der Steigung eingesetzt werden.
- Nun muss die Gleichung nach
x2aufgelöst werden (oder: die Gleichung auflösen lassen). - Im Anschluss muss der x2-Wert in den Exponenten genommen werden.
- Über den Plot-Befehl kann nun eine Gerade zwischen den beiden Punkten (x1, y1) und (x2, y2) eingezeichnet werden.
Diese Vorgehensweise habe ich in der Funktion
refline()zusammengefasst:refline <- function(x1=NA, y1=NA, x2=NA, y2=NA, m=1, add=T, ...) { # Welchen Achsen (des letzten plots) sind logarithmisch? logX = par("xlog") logY = par("ylog") # Werte der logarithmischen Achsen umrechnen if(!is.na(x1) && logX) {x1 = log(x1)} if(!is.na(x2) && logX) {x2 = log(x2)} if(!is.na(y1) && logY) {y1 = log(y1)} if(!is.na(y2) && logY) {y2 = log(y2)} # Bestimmung der fehlenden Variablen if(is.na(x1)) { x1 = (y1 - y2 + m * x2) / m print("X1 wird berechnet") } else if(is.na(x2)) { x2 = (y2 - y1 + m * x1) / m print("X2 wird berechnet") } else if(is.na(y1)) { y1 = y2 + m * (x1 - x2) print("Y1 wird berechnet") } else if(is.na(y2)) { y2 = y1 + m * (x2 - x1) print(paste("Y2 wird berechnet", y2)) } # Werte der logarithmischen Achsen umrechnen if(!is.na(x1) && logX) {x1 = exp(x1)} if(!is.na(x2) && logX) {x2 = exp(x2)} if(!is.na(y1) && logY) {y1 = exp(y1)} if(!is.na(y2) && logY) {y2 = exp(y2)} # Einzeichnen if(add) { lines(x=c(x1, x2), y=c(y1, y2), ...) } # Ausgabe data.frame( x1, y1, x2, y2, m , xmin=min(x1, x2), xmax=max(x1, x2) , ymin=min(y1, y2), ymax=max(y1, y2) ) }Die Besonderheiten der Funktion
refline()sind:- Es wird automatisch die fehlende Koordinate bestimmt.
- Es wird erkannt, welche der Achsen logarithmisch sind.
- Wichtige Werte der Geraden werden bei Aufruf zurückgegeben. Im Anschluss können sie verwendet werden, z.B. um Texte an die Enden der Geraden zu schreiben.
- Die Gerade wird (auf Wunsch:
add=T) in den vorigen Plot eingetragen. - Grafik-Parameter werden an den Plot-Befehl weitergeleitet (
...).
Nun kann
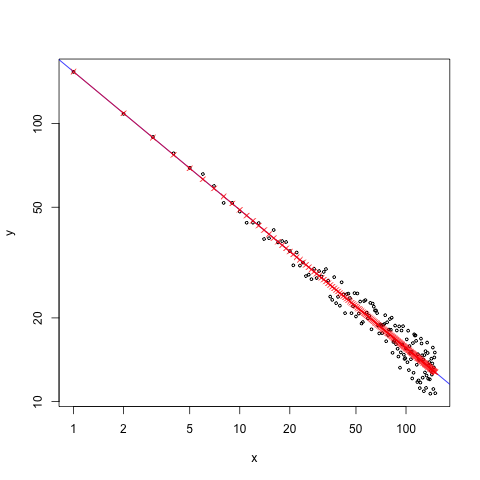
refline()genutzt werden, um die oben genannte Gerade (sowie eine weitere Gerade) in den Plot einzuzeichnen. Die Variablenrl1undrl2dienen dazu, die Anfangs- und End-Punkte zu speichern. Mit den gespeicherten Werten werden Anschluss die Texte positioniert.#png("log-gerade_2.png", width=480, height=360) #par(cex =1.5, mar=c(4,4,0,0)+.01) plot(x, y, log="xy", xaxt="n", yaxt="n") sfsmisc::eaxis(side=1, at=10^c(0:3)) sfsmisc::eaxis(side=2, at=10^c(-4,-2,0)) rl1 = refline(x1=1e1, y1=1e-1, x2=2e2, m=-1, col="red") text(x=rl1$x2, y=rl1$y2, labels=paste0(" Slope: ", rl1$m), adj=0, col="red") rl2 = refline(x1=8e0, y1=1e-2, x2=1e2, m=-2, col="blue") text(x=rl2$x2, y=rl2$y2, labels=paste0(" Slope: ", rl2$m), adj=0, col="blue") #dev.off()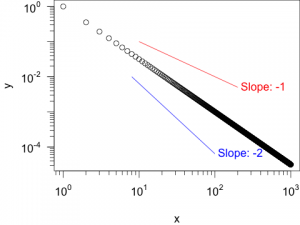
Darstellung einer Potenzfunktion mit einer Steigung von -1.5. Zusätzlich wurden Referenz-Steigungen von -1 und -2 eingezeichnet. - Hinweis: Als Parameter für die Funktion
refline()muss ein vollständiges und ein unvollständiges Koordinaten-Tupel, sowie die gewünschte Steigung angegeben werden. Der Punkt (x2, y2) muss dabei nicht immer rechts vom Punkt (x1, y1) liegen. Vielmehr hängt es von den gewählten Werten ab, wie die Punkte zueinander liegen. Die Wertex1undy1bestimmen gemeinsam immer den einen Punkt und die Wertex2undy2gemeinsam den anderen Punkt. - Wie ich oben bereits erwähnt habe, funktioniert die Berechnung des fehlenden Punktes der Gerade auch in Plots mit zwei linearen, oder nur einer logarithmischen Achse:
Im Falle z.B. einer logarirhmischen Y-Achse werden dann nur die Y-Koordinaten logarithmiert. Hier einige Beispiele:# Linear plot(x, y) r1 = refline(x1=0, x2=500, y1=1, m=-0.0005, col="blue") text(x=r1$xmax, y=r1$ymin, labels=paste0(" Steigung: ", r1$m), adj=0) # Y-logarithmisch plot(x, y, log="y", yaxt="n") sfsmisc::eaxis(side=2, at=10^c(-4,-2,0)) r2 = refline(x1=10, x2=500, y1=1, m=-0.002, col="red") text(x=r2$xmax, y=r2$ymin, labels=paste0(" Steigung: ", r2$m), adj=0)