Ich habe gerade eben folgende Fehlermeldung nach dem Start von Ubuntu bekommen:
Auf dem Datenträger „Wurzelordner des Dateisystems“ ist nur noch XXX kB Speicherplatz verfügbar.
In meinem Falle war XXX gleich 0. Es war also höchste Zeit, dass ich mal wieder unnötige Dateien von meiner System-Partition lösche. Ich hatte allerdings längst wieder vergessen, was man alles machen kann. Daher habe ich nun eine kleine Liste zusammengestellt:
-
Zunächst habe ich den Inhalt des temporären Verzeichnisses gelöscht.
1 2
# Temporäreres Verzeichnis leeren rm -r /tmp/*
Darin hatten sich Fehlermeldungen von apport angesammelt, die bei Programmabstürzen erstellt worden waren. Teilweise konnten diese aber nicht abgesendet werden, weil keine Internetverbindung bestand. In meinem Falle hatten sich über die Jahre mehr als 1.5 GB angesammelt.
-
Im Anschluss habe ich heruntergeladene Paket-Dateien, sowie nicht mehr benötigte Pakete gelöscht:
1 2 3 4
# Paketdateien löschen sudo apt-get clean # Nicht mehr benötigte Pakete löschen sudo apt-get --purge autoremove
Letzterer Befehl hat früher scheinbar auch nicht mehr benötigte Kernel-Versionen gelöscht (UbuntuUsers Forum). Das ist jetzt allerdings nicht mehr der Fall.
-
In regelmäßigen Abständen sollte man auch das Programm
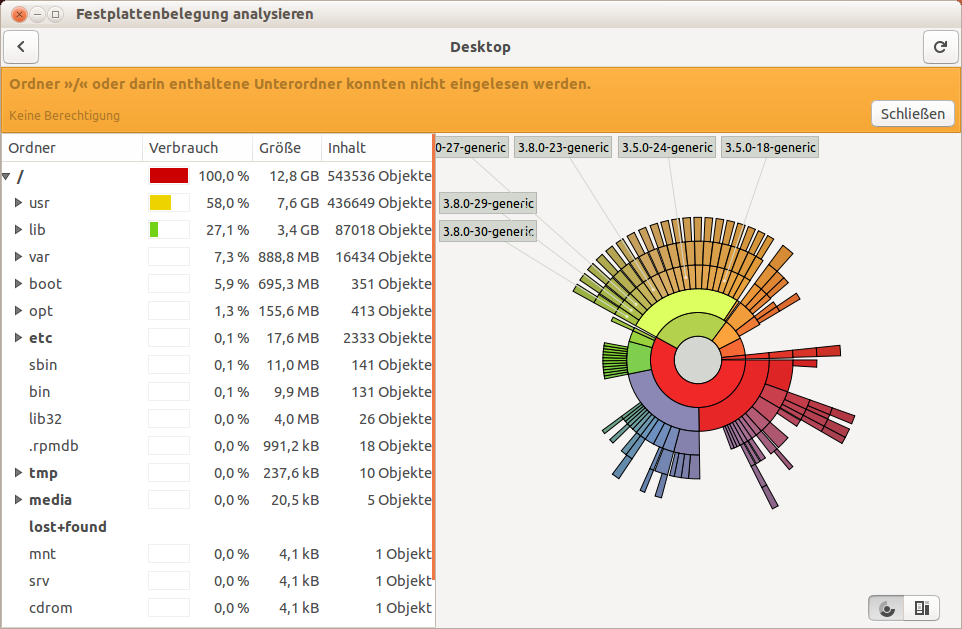
baobab(„Festplattenbelegung analysieren“) aufrufen. Damit kann man herausfinden, welche Verzeichnisse besonders viele Daten enthalten. In meinem Falle habe ich gesehen, dass sich viele Kernel-Versionen angesammelt hatten (Ordner:/usr/srcund/lib/modules):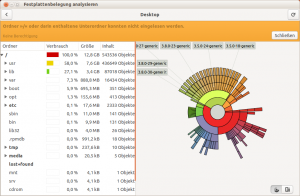
Das Programm „baobab“ stellt die Größe von Ordnern grafisch dar. In diesem Fall kann man erkennen, dass ein großer Teil der Partition mit alten Kernel-Versionen belegt ist. Wie im UbuntuUsers-Forum beschrieben, kann man im Terminal ähnlich vorgehen:
1 2
# Platzbedarf der Ordner im Wurzelverzeichnis anzeigen sudo du -h / --max-depth=1
Im Anschluss kann man sich weiter auf die Suche machen und z.B. eine Liste der installierten Kernel-Versionen ausgeben lassen:
1 2
# Installierte Kernel-Versionen anzeigen lassen dpkg -l linux-image-*
Die Ausgabe könnte dann folgendermaßen aussehen:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69
Da bei mir vor allem die Zahl der alten Linux-Kernel ein Problem war, habe ich einige davon gelöscht. Wie im Wiki von UbuntuUsers beschrieben, habe ich dazu in der Paketverwaltung
Synapticnach- linux-image-
- linux-headers-
gesucht und entsprechende Pakete vollständig entfernt. Mindestens eine ältere Version sollte man allerdings behalten. Dadurch habe ich 3.5GB frei machen können.
Wenn man die Kernel im Terminal entfernen möchte, sind diverse Lösungen im Netz zu finden: LinuxMintUsers.de, webupd8.org, linuxundich.de, UbuntuUsers Forum
-
Große Dateien können sich auch im Verzeichnis
/var/logansammeln. Das war bei mir allerdings nicht der Fall, was ich folgenden Befehlen überprüft habe:# Dateien sortiert nach Nutzungsdatum auflisten ls -aluh /var/log # Größe des gesamten Ordners ausgeben lassen sudo du -sh /var/log
-
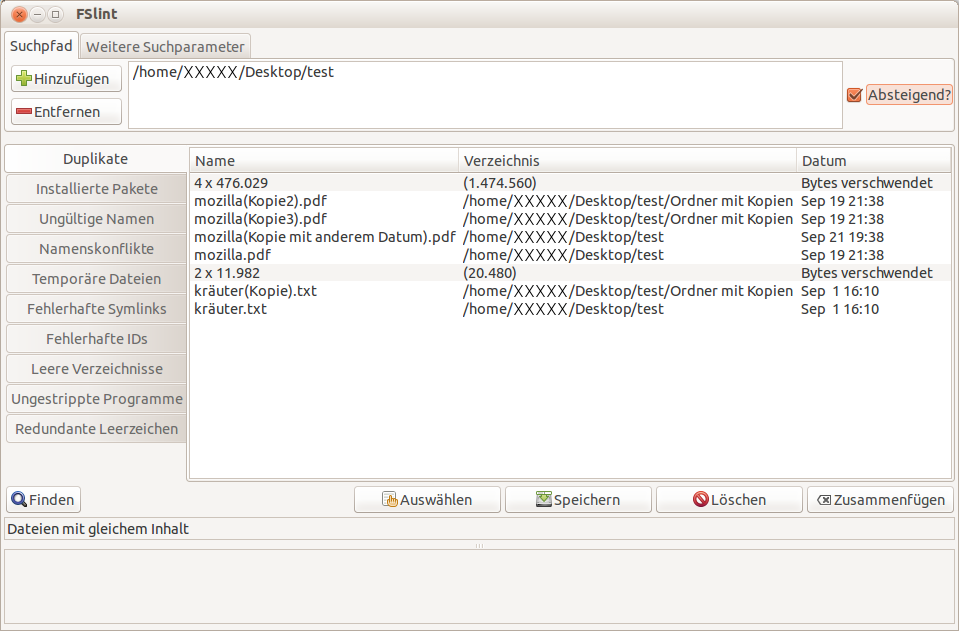
Wenn man im eigenen Home-Verzeichnis Ordnung schaffen möchte, bietet sich das Programm FSlint an. Nach der Installation des Programmpaketes
fslint, lässt sich das Programm über den Befehlfslint-guistarten. Im Anschluss kann man viele ungenutzte Dateien und Ordner suchen und ggf. direkt löschen:- Duplikate
- Temporäre Dateien (außerhalb des Verzeichnisses
/tmp) - Leere Verzeichnisse
- Fehlerhafte Symlinks
- …

Das Programm FSlint kann unter anderem Dateien mit identischem Inhalt finden. Dabei spielt es keine Rolle, ob die Dateien unterschiedliche Namen oder Erstellungsdaten haben.