R bietet verschiedene Möglichkeiten, seine Datenreihen in Plots unterscheidbar zu machen. Dazu gibt man in den Plot-Befehlen den zu ändernden Parameter, sowie einen Zahlenwert an. Ich vergesse allerdings immer, welche Zahl zu welcher Farbe oder zu welchem Linientyp gehört. Daher liste ich in diesem Artikel Zahlenwerte für folgende Parameter auf:
- Typen von Linien (
lty).
Beispiel:plot(c(1:10), type="o", lty=3). - Farben (
col).
Beispiel:plot(c(1:10), type="o", col=4). - Typen von Punkten / Sybole (
pch; point character).
Beispiel:plot(c(1:10), type="o", pch=5).
Linientypen
In R gibt es sechs verschiedene Typen von Linien. Die Zahlen für die Linientypen werden mit einer Periode von sechs „recycled“. Dadurch entspricht der Typ sieben (7) wieder dem Typen eins (1), eine Linie vom Typ acht (8) sieht aus wie eine Linie vom Typen zwei (2) und so weiter. Für jeden der Linien-Typen gibt es auch einen Namen (siehe auch Beschreibung des Parameters lty in der R-Hilfe zu par(): ?par):
0: „blank“; unsichtbare Linie (=> wird nicht gezeichnet)1: „solid“2: „dashed“3: „dotted“4: „dotdash“5: „longdash“6: „twodash“
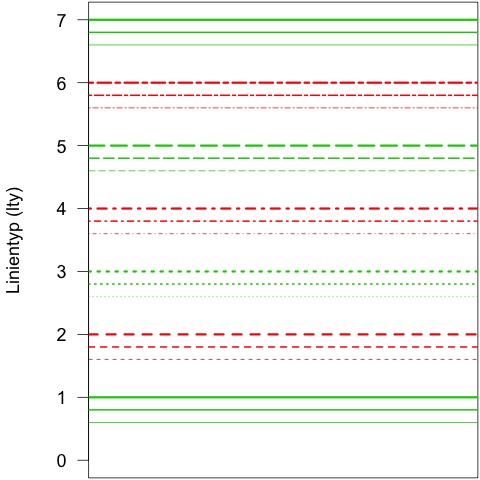
Das oben stehende Bild habe ich mit folgendem Code erzeugt:
# 6 Linientypen
png("linientypen.png")
par(mar=c(0,4,0,0)+.1, cex=1.5)
plot(1,1, type="n", ylim=c(0, 7), xaxt="n", xlab="", ylab="Linentyp (lty)", las=1)
abline(h=c(0:7), lty=c(0:7), lwd=3, col=c(2,3))
abline(h=c(0:7)-0.2, lty=c(0:7), lwd=2, col=c(2,3))
abline(h=c(0:7)-0.4, lty=c(0:7), lwd=1, col=c(2,3))
dev.off()
Farben
In der Standard-Palette von R befinden sich acht verschiedene Farben. Dazu kommt noch der Wert 0, bei dem die Hintergrundfarbe als Farbe verwendet wird. Die Farben werden mit einer Periode von acht „recycled“. Durch diese fortlaufende Wiederholung, entspricht die Farbe neun (9) der Farbe eins (1), die Farbe zehn (10) wieder der Farbe zwei (2) und so weiter. Anstatt einer Zahl kann man auch direkt den RGB-Farbwert angeben (z.B. plot(1, 1, col="#000000") anstatt plot(1, 1, col=1) ). Weitere Details gibt es im Bereich „Color Specification“ in der R-Hilfe zu den Grafik-Parametern (?par).
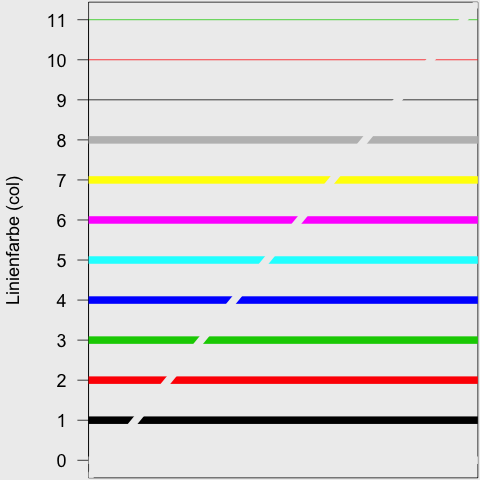
Für das vorangegangene Bild habe ich folgenden Code verwendet:
# 8 LinienFarben
png("linienfarben.png")
par(mar=c(0,4,0,0)+.1, cex=1.5, bg="#eeeeee")
plot(1,1, type="n", ylim=c(0, 11), xlim=c(0, 11), xaxt="n", xlab="", ylab="Linenfarbe (col)", las=1, lab=c(1,11,0))
abline(h=c(0:11), lty=1, lwd=c(rep(10,9), rep(1,9)), col=c(0:11))
abline(a=0, b=1, lwd=10, col=0)
dev.off()
Punkttypen / Symbole
Um den Punkttyp zu definieren, kann entweder ein einzelnes Zeichen oder eine Zahl angeben werden. In der Hilfe zum Befehl par() (?par oder ?graphics::par) steht dazu:
Note that only integers and single-character strings can be set as a graphics parameter (and not NA nor NULL)
Eine detaillierte Liste gibt es in der R-Hilfe zur Funktion points() (?points; Bereich „‚pch‘ values“). Hier eine kurze Zusammenfassung:
- Zeichen
0–18: S-kompatible Vektor Symbole - Zeichen
19–25: Weitere R Vektor Symbole. Die Zeichen21–25können mit Hilfe vonbginnerhalb des plot-Befehls (hier:points()) eingefärbt werden. Achtung: Die Angabe vonbginnerhalb vonpoints()hat hier eine andere Auswirkung als die Angabe vonbginnerhalb vonpar()(z.B.par(bg="#ff00ff")). Durch letzteres setzt man die Hintergrundfarbe der gesamten Plot-Fläche. - Zeichen
26–31: Werden ignoriert - Zeichen
32–127: ASCII Zeichen
In der folgenden Grafik werden die die ersten 26 Zeichen dargestellt (+ zwei negative Werte).
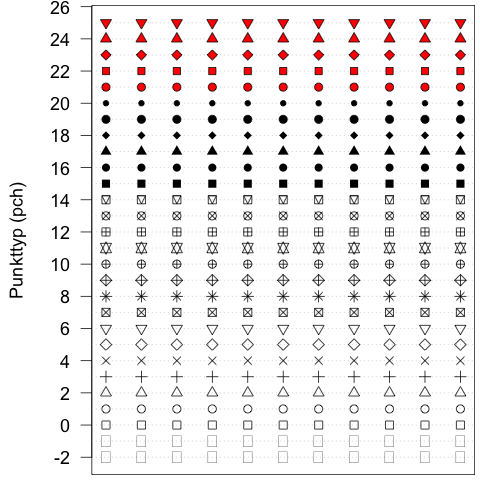
Das oben stehende Bild wurde mit folgenden Befehlen erzeugt:
# 25 Punkt-Typen
png("punkttypen.png")
par(mar=c(0,4,0,0)+.25, cex=1.5)
plot(1, 1, type="n", ylim=c(-2, 25), xlim=c(0, 10), xaxt="n", xlab="", ylab="Punkttyp (pch)", las=1, lab=c(2,15,0))
abline(h=c(-2:25), lty=3, lwd=1, col="#cccccc")
for (typ in -2:25) {
points(x=c(0:10), y=c(rep(typ,11)), pch=typ, bg="red")
}
dev.off()