
Stell Dir vor, Du hast die Länge von 1000 Fischen gemessen. Im Anschluss möchtest Du die eine Häufigkeitsverteilung (Histogramm) der Größen erstellen. Je nachdem wie genau du gemessen hast, wirst du keine zwei Fische mit der gleichen Länge finden. Daher bist Du gut beraten, die Daten zunächst in bestimmte Längenklassen einzuteilen (z.B. „Anzahl von Fischen zwischen 23cm und 24cm“). Für diese Klassifizierung (binning) steht Dir in R die Funktion hist() zur Verfügung.
Nehmen wir mal an, die Längen der Fische folgen einer Normalverteilung. Im Durschnitt haben die Fische eine Länge von 25cm (± 5cm)
1 2 3 | # Ziehe Eintausend Zufallszahlen aus einer Normalverteilung # (Mittelwert: 25; Standardabweichung: 5) laengen = rnorm(n=1e3, mean=25, sd=5) |
Mit der Funktion hist() kannst Du die Daten nun in Klassen einteilen und plotten lassen.
1 2 3 | # Klassifiziere die Daten # (=Erstelle eine Histogramm und stelle es dar) gebinnt = hist(laengen, plot=TRUE) |
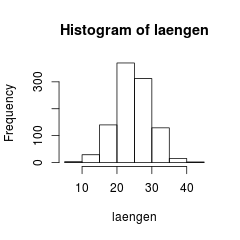
hist() erstellt nun eine list, in der die Klassengrenzen (breaks), die Häufigkeiten (counts), Dichten (densitiy) und Klassenmitten (mids), sowie der Name der ursprünglichen Variable (xname) und die Information, ob die Klassen alle gleich groß sind (equidist), gespeichert werden:
1 | str(gebinnt) |
List of 7 $ breaks : num [1:9] 5 10 15 20 25 30 35 40 45 $ counts : int [1:8] 3 29 140 370 312 129 15 2 $ intensities: num [1:8] 0.0006 0.0058 0.028 0.074 0.0624 0.0258 0.003 0.0004 $ density : num [1:8] 0.0006 0.0058 0.028 0.074 0.0624 0.0258 0.003 0.0004 $ mids : num [1:8] 7.5 12.5 17.5 22.5 27.5 32.5 37.5 42.5 $ xname : chr "laengen" $ equidist : logi TRUE - attr(*, "class")= chr "histogram"
Für weitere Analysen kannst Du selbst noch die Breite der Klassen (breite) und den Anteil der Klassen an der Stichprobe (anteil) zur Liste hinzufügen:
1 2 | gebinnt$breite = diff(gebinnt$breaks) gebinnt$anteil = gebinnt$counts / sum(gebinnt$counts) |
Eigene Klassenbreiten festlegen
Du hast natürlich auch die Möglichkeit, selbst Klassengrenzen (breaks) anzugeben. Die Klassen müssen auch nicht alle gleich Groß sein. Bei einigen Daten können z.B. logarithmische Bin-Größen sinnvoll sein.
1 2 3 4 | # Klassen mit Klassenbreite 1 (cm) erstellen gebinnt = hist( laengen, plot=T, breaks=c(0:50) , xlab="Länge (cm)", ylab="Häufigkeit", main="Häufigkeitsverteilung") |
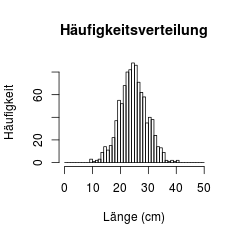
Hierbei muss man allerdings darauf achten, dass keiner der Werte ausgeschlossen wurde, weil er ausserhalb der gewählten Klassen lag bzw. auf die untere (oder obere) Klassengrenze gefallen ist.
Fehler in hist.default(laengen, plot = T, breaks = c(15:50), xlab = "Länge (cm)", : einige 'x' nicht gezählt: evtl. überdecken die 'breaks' nicht den gesamten Bereich von 'x'
Daher sollte man immer prüfen, ob die Summe der Werte in den Klassen auch tatsächlich der Stichprobengröße entspricht.
# Sind alle Messwerte der Stichpobe im Histogramm berücksichtigt? sum(gebinnt$counts) |
Eventuell muss man dann weitere Klasse hinzunehmen, bzw. die untere (oder obere) Klassengrenze zu einer Klasse hinzu zählen (Option include.lowest=T).
Alternativen
Alternativ zur Funktion hist() könnte man ein Histogramm auch durch die Anwendung der Funktion table() auf gerundete Daten (round()) erstellen: table(round(daten)).
Die Funktion table() ist dazu gedacht die „Anzahl gleicher Werte zu ermitteln“. Das entspricht aber nicht ganz dem Gedanken der Klassifizierung.