TeXstudio wurde erstellt, um die Arbeit mit LaTeX zu vereinfachen. Eine Möglichkeit ist die Verwendung sogenannter Makros (oder Macros). Mit der Hilfe von Markos kann man umfangreiche Anweisungen ausführen lassen oder LaTeX-Anweisungen in den Quelltext einfügen. In diesem Artikel liste ich solche Markos auf, die ich derzeit verwende. Weitere Möglichkeiten von Makros werden im Handbuch von TeXstudio beschrieben.
Makros können in TeXstudio unter Makros / Makros bearbeiten verwaltet werden. Ich benutze Makros vor allem um LaTeX-Anweisungen direkt beim Tippen in meinen Quelltext einfügen zu lassen. Dazu dienen Auslöseimpulse (Trigger) und deren Abkürzungen (Abbreviations). Legt man z.B. ein Makro mit dem Trigger BILD an, so wird nach der Eingabe von BILD dieser Text durch den definierten LaTeX-Text ersetzt.
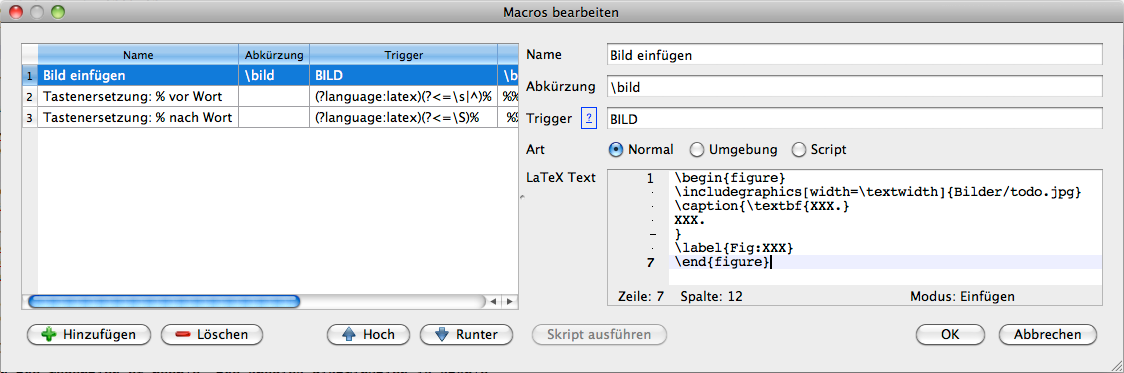
Makro: Bild einfügen
Nach der Eingabe von \bild oder BILD, werden diese Zeichenketten durch LaTeX-Befehle zum Einbinden eines Bildes ersetzt. Damit die unten stehenden Befehle funktionieren, muss in der Präambel das Paket graphicx eingebunden werden (z.B. \usepackage[pdftex]{graphicx}).
| Name: | Bild einfügen |
| Trigger: | BILD |
| Abbreviation: | \bild |
| LaTeX-Text: |
\begin{figure}
\includegraphics[width=\textwidth]{Bilder/todo.jpg}
\caption{\textbf{XXX.}
XXX.
}
\label{Fig:XXX}
\end{figure}
|
Makro: Tabelle einfügen
Nach der Eingabe von \tabelle oder TABELLE, werden diese Zeichenketten durch LaTeX-Befehle für eine Tabelle ersetzt. Damit die unten stehenden Befehle funktionieren, müssen in der Präambel zwei Pakete eingebunden werden:
\usepackage{tabularx}– Tabelle, die automatisch an die Breite der Seite angepasst werden kann (über ein X bei der Angabe der Ausrichtung innerhalb der Tabelle).\usepackage{booktabs}– Für die Befehle\toprule,\midruleund\bottomrule.
| Name: | Tabelle einfügen |
| Trigger: | TABELLE |
| Abbreviation: | \tabelle |
| LaTeX-Text: |
\begin{table}
\caption{TabellenTitel}
\label{Tab:Parameter}
\begin{tabularx}{\textwidth}{ llX }
\toprule
Parameter & Typical value & Meaning\\
\midrule
$XXX$ & $XXX$ & XXX.\\
$XXX$ & $XXX$ & XXX.\\
\bottomrule
\end{tabularx}
\end{table}
|
Weitere Informationen zu Triggern
Trigger werden als Reguläre Ausdrücke interpretiert. Daher können sie deutlich mehr, als nur eine zu ersetzende Zeichenkette definieren:
Wenn dieser Triggertext in einem tex-Dokument geschrieben wird, so wird durch das aktuelle Makro ersetzt.
Wenn der Trigger mit (?<=etwas) anfängt, so passiert dies nur wenn "etwas" vor den restlichen Teil des Triggers geschriben wurde. Da der Triggertext kein einfacher Suchtext, sondern eine regulärer Suchausdruck ist, kann (?<=\S) verwendet werden, um Ersetzungen nach einem Wort und (?<=\s|^) um Ersetzungen vor einem Wort auszulösen. Man kann den speziellen Wert ?txs-start verwenden, um das Skript bei txs start zu starten.