
Wer Potenzgesetze (PowerLaws) in Daten entdecken möchte, bestimmt die Steigung in einem Graphen mit logarithmischen Achsen (log-log-Plot). In der Regel möchte man diese Steigung dann in der Graphik als Regressionsgerade darstellen. In R ist genau diese Darstellung nicht ganz einfach, da die Funktion abline() hier versagt. Im folgenden Artikel möchte ich zeigen, wie man die Schätzung seines Modells dennoch in den Plot eintragen kann.
Wir haben Daten, die einem Potenzgesetz folgen (mit etwas statistischer Schwankung).
x = c(1:150)
y = x^-.5 * 155 + (runif(length(x), min=-3, max=3))
Diese Daten plotten wir in einer Graphik mit zwei logarithmischen Achsen.
plot(x, y, log="xy", cex=.5)
Da wir ein Potenzgesetz vermuten, berechnen wir die Parameter (Steigung und Y-Achsenabschnitt) des linearen Modells (lm()) der logarithmierten Daten (siehe auch Stackoverflow):
model = lm(log(y) ~ log(x))
model
In einem doppelt-logarithmischen Plot gibt es natürlich keinen Y-Achsenabschnitt (die Null wird nie erreicht). Beim Aufruf der Funktion abline(model) wird die Regressionsgerade (besonders bei verschobenen Funktionen) an der falschen Stelle dargestellt. Daher muss man für sein lineares Modell Werte vorhersagen (mit predict() bzw. predict.lm), die man im Anschluss in den Exponenten nimmt und als Linie (lines()) zum Plot hinzufügt (siehe auch Stackoverflow: Beitrag 1 und Beitrag 2).
# Schätzung für 2 Punkte machen
neuX=c(1e-10,1e10)
lines(neuX, exp(predict(model, newdata=list(x=neuX))) ,col="blue", type="o", pch=2)
# Schätzung für Datenpunkte machen
lines(x, exp(predict(model, newdata=list(x=x))), col="red", type="o", pch=4)
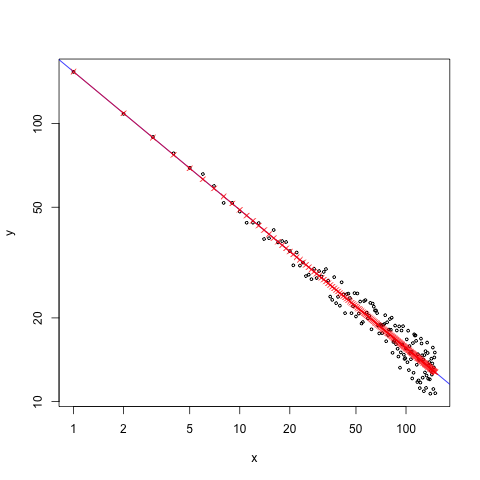
Hinweise: Der Variablenname in der Liste von newdata muss genau der selbe sein, wie der Name der Variablen, die beim Aufruf des linearen Modells verwendet wurde.
- Hat man seine Daten z.B. in einem
data.framegespeichert, sollte man das lineare Modell mittelswith()aufrufen, anstatt die Bereiche mit Hilfe des$-Selektors auszuwählen. - Wenn man das lineare Modell nur für einen Teil seiner Daten verwenden möchte, so sollte man die Option
subset=vonlm()verwenden, anstatt Teile des Vectors mit Hilfe der eckigen Klammern auszuwählen.
Die folgenden Beispiele zeigen zwei Mögliche Schreibweisen, eine lineare Regression für die die Datensätze 40 bis 80 einzuzeichnen. Die Daten dafür sind:
x = c(1:150)
y = x^-.5 * 155 + (runif(length(x), min=-3, max=3))
daten = data.frame(x,y)
range = c(40:80)
Beispiel 1: with() wird nur für den Aufruf des lm() verwendet. die Ergebnisse der Regression werden in model gespeichert.
plot(daten$x, daten$y, log="xy", cex=.5)
model = with(
data = daten,
expr = { model = lm(log(y) ~ log(x), subset=range); model }
)
model
lines(
x[range]
, exp(predict(model, newdata=list(x=x[range])))
, col="red"
, type="o"
, pch=4
)
Beispiel 2: with() wird für die gesamte Behandlung der Daten verwendet (plot(), lm(), lines()).
with(
data = daten,
expr = {
plot(x, y, log="xy", cex=.5)
model = lm(log(y) ~ log(x), subset=range)
lines(
x[range]
, exp(predict(model, newdata=list(x=x[range])))
, col="red"
, type="o"
, pch=4
)
}
)